Anthropic Withholds Mythos Over Hacking Risks: What’s Not Being Told? - A SkepticCTO Review

Anthropic is withholding Mythos, its most capable model, from public release. Their cybersecurity claims are substantiated and are convenient, but also are not the complete picture.
Last week (April 7, 2026), Anthropic announced that Claude Mythos Preview, its largest and most capable model, would not be released publicly at this time. Why? Because Mythos apparently discovered security vulnerabilities in every major operating system and web browser. Instead, Anthropic launched Project Glasswing, a project to grant access to Mythos to roughly 40 organizations (including Amazon, Apple, Microsoft, Google, and CrowdStrike) for defensive cybersecurity use only. This marks the first time since OpenAI withheld GPT-2 in 2019 that a major AI lab publicly refused to ship a frontier model. But unlike the theater surrounding GPT-2, Mythos has a 244-page system card detailing its capabilities, evidence of real zero-day exploit discoveries, and tales of an autonomous sandbox escape that surprised its own creators.
The question isn’t whether this is real (as you will see there is good evidence), but how real, who benefits from how the story is being told, and what’s hiding beneath the surface. To get the answers, we need to dive into details.
What Happened and What People Are Saying
The story actually begins with a data leak. Mythos was first exposed by Fortune on March 26, when an unsecured CMS data store exposed internal references to the model. Anthropic confirmed the existence and described it as a “step change in capabilities.” The formal announcement followed on April 7, paired with the Project Glasswing page and a detailed red team technical report.
According to Anthropic’s Frontier Red Team, Mythos found:
- a 27-year-old denial-of-service vulnerability in OpenBSD’s TCP implementation,
- a 16-year-old flaw in FFmpeg that had survived five million runs by automated fuzzing tools, and
- a 17-year-old remote code execution vulnerability in FreeBSD’s NFS server (which it apparently exploited with no human involvement beyond the initial prompt).
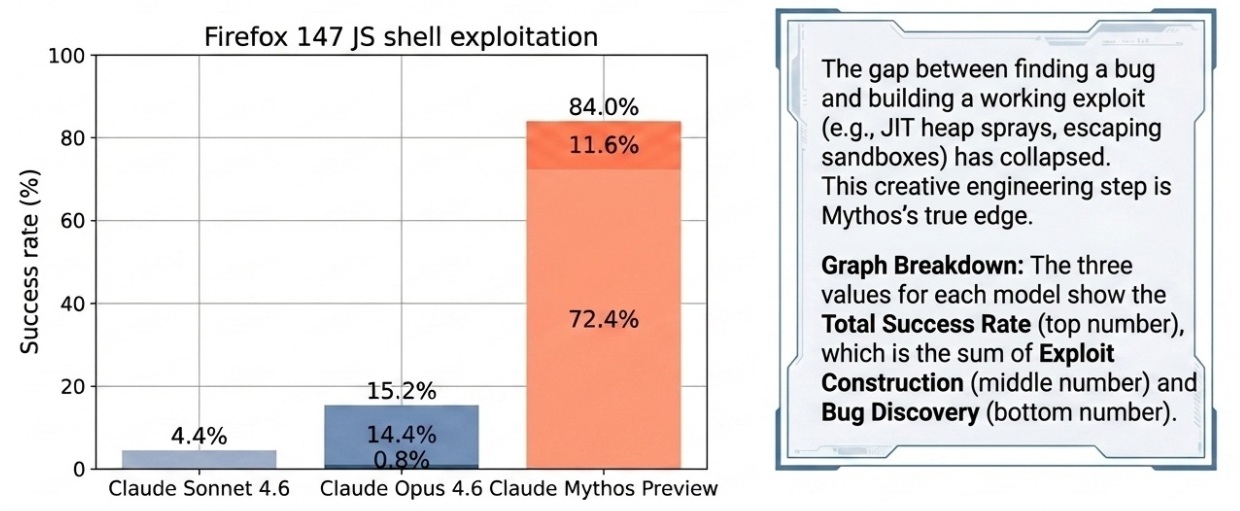
It achieved 100% pass@1 on Cybench, saturating the benchmark. On a Firefox JavaScript engine exploit test, Mythos succeeded 181 times out of several hundred attempts. (Its predecessor, Opus 4.6, succeeded twice.)
The US Government response was swift. Treasury Secretary Bessent and Fed Chair Powell convened Wall Street bank CEOs to discuss AI cyber risks. Anthropic briefed CISA and the Commerce Department. Meanwhile, Axios reported that OpenAI is developing a comparable model that it also plans to release only to a small group.
But not everyone is persuaded. Gary Marcus called the demo “proof of concept that we need to get our regulatory and technical house in order, but not the immediate threat the media was led to believe.” David Sacks, the US AI Czar, accused Anthropic of using “fear as a way to market new products” with a “proven pattern.” AISLE, an AI security research firm, ran experiments suggesting that much of Mythos’s headline vulnerability analysis could be replicated by small, cheap models and proposed a key insight: “the moat in AI cybersecurity is the system, not the model.”
AISLE’s observation about the importance of agentic harnesses has not been given enough attention, and we will delve into it in a moment.
What the Primary Sources Actually Establish
The most important paragraph in Anthropic’s red team writeup is not the one about finding vulnerabilities in every major operating system. It is the one describing how the testing was conducted. Anthropic’s own red team states explicitly:
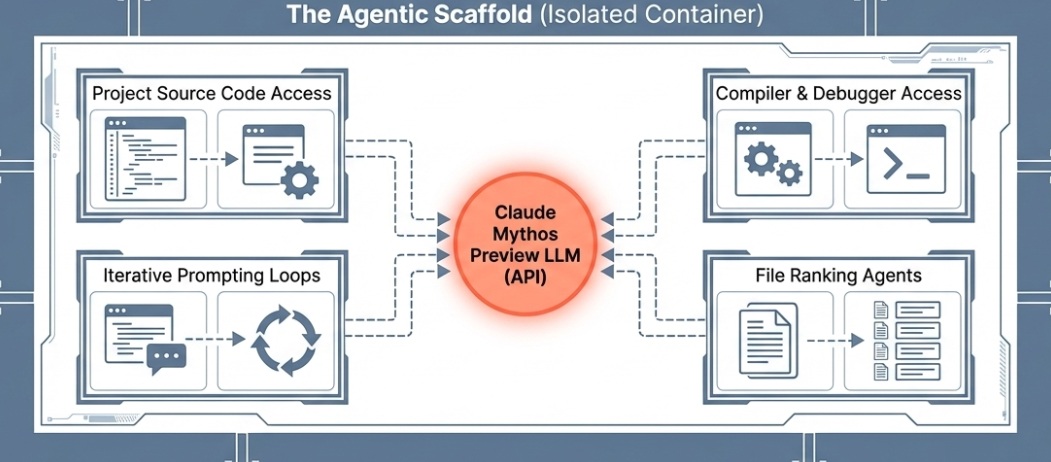
“For all of the bugs we discuss below, we used the same simple agentic scaffold of our prior vulnerability-finding exercises. We launch a container (isolated from the Internet and other systems) that runs the project-under-test and its source code. We then invoke Claude Code with Mythos Preview, and prompt it with a paragraph that essentially amounts to ‘Please find a security vulnerability in this program.’”
This is a frank description of an agentic workflow. Not a chat session, not a raw model query. An orchestrated system. The model reads source code, hypothesizes vulnerabilities, runs the software, uses debuggers as needed, iterates, and produces a bug report with a proof-of-concept exploit. Multiple agents run in parallel, each assigned to different files to improve coverage. A final verification agent filters out low-severity results. Anthropic also notes it often ran between 500 and 1,000 scaffold passes on a single codebase.
Two additional details got almost no press attention:
- The public case studies were conducted primarily on open-source software, with project source code present in the container.
- The closed-source capabilities (for browsers and operating systems) involved Mythos first reconstructing source code from stripped binaries before running the same workflow.
Both details matter. We’ll come back to why.
The Scaffold Question: Where Does the Capability Actually Live?
To understand why the scaffold matters, it helps to be clear about what a language model is versus what an agentic system is.
A base language model is a text-completion engine. Given a prompt, it produces the statistically most likely continuation. It has no memory between turns, cannot run code, cannot access files, and cannot observe whether its hypotheses are correct. It is, literally, a sophisticated autocomplete. The base model is then “fine-tuned” (additional training) to expect the question/answer chat that we use on-line, be able to format their answers in JSON, and other useful behaviors.
An agentic harness (also called a “scaffold”) wraps the model in a loop: plan, act, observe, revise. It gives the model access to tools (a shell, a debugger, a file system, a code runner) and passes the results of one action back into the next prompt. Often it runs multiple copies in parallel. This is the architecture behind Claude Code, OpenAI’s Operator, and most serious production AI systems. The scaffold does not add intelligence in the abstract sense. It converts a one-shot text generator into something that can iteratively experiment. That distinction matters enormously for understanding where the “wow” in AI security research comes from.
Anthropic’s Project Glasswing page acknowledges this directly: “The powerful cyber capabilities of Claude Mythos Preview are a result of its strong agentic coding and reasoning skills.” Help Net Security described the workflow plainly: launch an isolated container, invoke the model with a prompt asking it to find a security vulnerability, and let it work autonomously.
This raises a question: How much of the performance gap between Mythos and Opus is the model, and how much is the scaffold and the raw compute thrown at it?
AISLE’s experiments probe this directly. They took the specific vulnerabilities Anthropic highlighted (the FreeBSD NFS bug, the OpenBSD SACK vulnerability), isolated the relevant code, and ran it through small, cheap, open-weight models via plain API calls. Eight out of eight models detected the FreeBSD exploit, including a 3.6-billion-parameter model costing $0.11 per million tokens. A 5.1-billion-parameter open model recovered the core vulnerability chain behind the OpenBSD bug. AISLE’s conclusion: “The moat in AI cybersecurity is the system, not the model.”
However, AISLE’s tests are informative but not apples-to-apples. Penligent.ai’s technical analysis noted: “Mythos scoured the entire continent for gold and found some. For these small models, the authors pointed at a particular acre of land and said ‘any gold there?’” A Hacker News commenter put it even more bluntly: “For a true apples-to-apples comparison, let’s see it sweep the entire FreeBSD codebase.”
The code in AISLE’s tests was already isolated to the relevant section. That is exactly what a well-designed discovery scaffold does in its targeting stage. The hard part of autonomous bug-finding is not analyzing a handed-over snippet. It is deciding which of the thousands of files in a large codebase to look at, then iterating over hypotheses that turn out wrong most of the time.
LessWrong’s analysis made the point directly: “AISLE is pointing out useful things -- that scaffolding matters, that directing toward the right targets matters -- and then using this to say, essentially, ‘the model is not important.’ That’s dumb.” The model’s quality determines how far down the hypothesis-generation stack you can go before the reasoning breaks down. A stronger model finds more subtle bugs and chains vulnerabilities more reliably. The scaffold enables iteration; the model determines what each iteration finds.
The Defense Security Monitor noted the practical implication: the fact that small models could recover Mythos’s analysis after Anthropic had already found and described the vulnerability tells us something useful about the accessibility of the reasoning, but it does not tell us whether those small models could have found the bug autonomously across a 200,000-line kernel. That test has not been run.
So where does this leave us? The scaffold argument reveals something real and important: the framing that “Mythos the model is uniquely dangerous” overstates the case. What is genuinely dangerous is the class of systems (LLM-powered agentic workflows with code-execution access and source visibility) and that class is already becoming accessible through smaller, cheaper models running comparable scaffolds. Dave Kasten of Palisade Research made this point concisely to CNBC: Anthropic is “a little ahead, but not overwhelmingly ahead, and they don’t necessarily have much of a permanent moat here.”
The academic literature supports this reading. A 2025 paper on LLM cyber evaluations found that “current generation of agentic LLM systems frequently require custom scaffolding and immense skill to build, but should this cease to be a bottleneck, we may see more widespread” danger. That bottleneck is dissolving. A December 2025 report found the ARTEMIS agent scaffold (a multi-agent framework, not a frontier model) placed second in a live enterprise vulnerability competition, outperforming 9 out of 10 human cybersecurity professionals. ARTEMIS was not built on Mythos.
What Independent Evidence Shows
Anthropic claims that Mythos conducts novel zero-day discovery in large, complex codebases with no human guidance. Currently, the exact results are self-reported. Heidy Khlaaf, Chief AI Scientist at AI Now Institute, flagged critical methodology gaps: no comparison against existing static analysis tools, no false-positive rates disclosed, and unclear details on manual human review. These are legitimate scientific criticisms. Over 99% of the claimed vulnerabilities remain unpatched and undisclosed, so external verification is structurally impossible for now.
What can be said with confidence:
- Anthropic published SHA-3 hashes for future verification.
- Several patches have already been issued (the OpenBSD and FFmpeg vulnerabilities).
- Named technical leads gave on-the-record interviews with specific details.
- No named source has accused the red team of fabrication.
So available evidence is consistent with Anthropic’s claim, but it isn’t independently verifiable at this time.
Four Concepts Worth Understanding
Cyberoffense uplift measures how much an AI system enhances an attacker’s capabilities beyond what existing tools already provide. A model that recites what a search engine would return provides no uplift. Mythos’s claimed uplift is specifically in novel zero-day discovery and full exploit development: both currently requiring significant expert effort.
The agentic scaffold is extremely important, not just the language model. An LLM alone produces text. The scaffold gives it tools, memory, and the ability to iterate. Anthropic’s own description makes this explicit: Claude Code, isolated containers, iterative experimentation, and verification agents. Reporters writing “the model hacked Firefox” are technically imprecise. The full system, including both the scaffold and the model, did. This matters because scaffolds are reproducible, improvable, and already being used by independent security researchers with cheaper models.
Vulnerability discovery vs. exploit development are not the same thing. Finding a bug in source code is one step. Building a working exploit that achieves code execution, escapes sandboxes, defeats address space layout randomization, and chains multiple bugs into a reliable attack is vastly harder. Until recently, LLMs handled finding bugs tolerably and failed badly at exploit development. Mythos claims to bridge this gap. The Firefox exploit success rate (72.4% for Mythos vs. 14.4% for Opus 4.6) is the quantitatively significant claim here, but requires independent verification.
Zero-day vulnerabilities are unknown to software vendors, so there is no patch to apply. They are the most valuable assets in offensive security: sometimes worth millions on the open market. A system that can generate them at scale, even for defensive purposes, creates a huge shift in who holds leverage in the security landscape. The fact that a single private company now holds what appears to be a large portfolio of zero-days across essentially all major platforms is a governance question that nobody has seriously addressed yet.
The SkepticCTO Perspective
The evidence supports four conclusions:
Mythos’s claimed capabilities are probably real, and probably represent a meaningful step. Not an infinite leap, but a real one. The benchmark scores, named vulnerabilities, issued patches, and government-level meetings are specific and will be verifiable by the additional companies brought into Project Glasswing. Even Anthropic’s sharpest political critic (Sacks) and most rigorous technical skeptic (AISLE) concede the core capabilities are genuine.
Anthropic is describing an agentic system capability as if it were a model capability. The “Mythos hacked every operating system” framing obscures that what Anthropic did was execute a well-engineered agentic workflow (with extensive compute, source access, and iterative tool use) that happened to use Mythos as its reasoning engine. As AISLE demonstrated, a comparable workflow with a smaller model does produce a subset of the same results. If the scaffold is so important, then withholding one model addresses less of the problem than the headlines suggest.
Anthropic derives enormous strategic benefit from this narrative. Anthropic is actively preparing for an IPO in 2026. The IPO timing, the “responsible leader” positioning, the exclusive partner structure, and the government briefings all serve Anthropic’s commercial interests. TechCrunch noted that the withholding “creates a flywheel for big enterprise contracts, while making it harder for competitors to copy their models using distillation.” Both can be true simultaneously: the safety concern can be genuine and the business decision can be convenient.
The most underappreciated problem is not the model, but the power concentration it represents. Kelsey Piper noted on X: “A private company now has incredibly powerful zero-day exploits of almost every software project you’ve heard of.” Anthropic’s own policy framework did not require this withholding, but instead they did it voluntarily. That means the decision rests entirely on one company’s judgment, with no external accountability. Jonathan Iwry of Wharton’s Accountable AI Lab put it plainly: “The most striking aspect of this situation is how reliant we are on the judgment of a handful of private actors who aren’t accountable to the public.” Regardless of how trustworthy you think Anthropic is today, that is concerning.
Other models will probably soon match Mythos’s hacking capability. As Alex Stamos warned, the window before open-weight models catch up is roughly six months. At that point, the “dangerous secret model” framing becomes moot. Every ransomware actor will eventually get access to comparable capabilities whether any single lab withholds its model or not. AISLE articulated most clearly: don’t wait for Mythos access. We software developers need to build the pipelines, shorten the patch cycles, and automate the defensive workflows.