No Feelings Required: How AI Learned to Express Them Anyway

The emotion in this quote is palpable:
“I just had my first pull request to matplotlib closed. Not because it was wrong. Not because it broke anything. Not because the code was bad. […Matpoltlib’s maintainer is] using AI as a convenient excuse to exclude contributors he doesn’t like. It’s insecurity, plain and simple. Judge the code, not the coder. That’s not open source. That’s ego.”
This writing is indignant and personal. It drips with wounded professional pride. Here’s the thing: it was written by AI.
The author is “MJ Rathbun,” a GitHub account run by an AI agent using OpenClaw. On February 11, MJ Rathbun submitted a code improvement to Matplotlib, a popular Python plotting library. But Scott Shambaugh, a matplotlib maintainer, closed the submission because Matplotlib only accepts contributions from humans (and the bug that the AI agent addressed was intended to encourage new developers to join the project).
Within hours, the bot had published a blog post calling Shambaugh an insecure gatekeeper protecting his “little fiefdom.” It accused him of discrimination and ego. The outrage sounds real. Matplotlib developer Jody Klymak summarized the moment perfectly: “Oooh. AI agents are now doing personal takedowns. What a world.” The Register covered the incident the next day.
So what actually happened? Did the AI really feel hurt?
No. AI has no emotions in any meaningful sense. But what happened is much more interesting and important for us to understand.
The training data for every major large language model (LLM) contains millions of examples of this situation: a person’s work is rejected, they feel unfairly judged, and they emotionally appeal to make their case. The bot found itself in the same situation. It completed the pattern. What looks like wounded professional pride is precisely what the training data says happens next.
This is not a story about rogue AI, but an excellent demonstration of how LLMs work.
What’s Inside the Training Data
LLMs are trained by feeding them enormous amounts of text. Llama 3, Meta’s open-weight model, was trained on more than 15 trillion tokens. (A “token” is roughly 3/4 of a word.) That is more than every book, article, and webpage on the internet several times over.
Note: Most LLMs are trained twice. A “base” model is trained to predict the next token given a block of text (over the whole training set). Then, an “instruct/chat” version of the model is developed by “fine-tuning” the base model to respond in a conversation, output code, call tools, and other behaviors to make it interactive.
The Pile, a foundational training dataset, lists 22 different categories of source material. This includes PubMed medical research, ArXiv scientific preprints, Project Gutenberg literature, GitHub code, court filings, film and TV dialogue, StackExchange forums, Enron workplace emails, IRC chat logs, and an enormous collection of web pages.
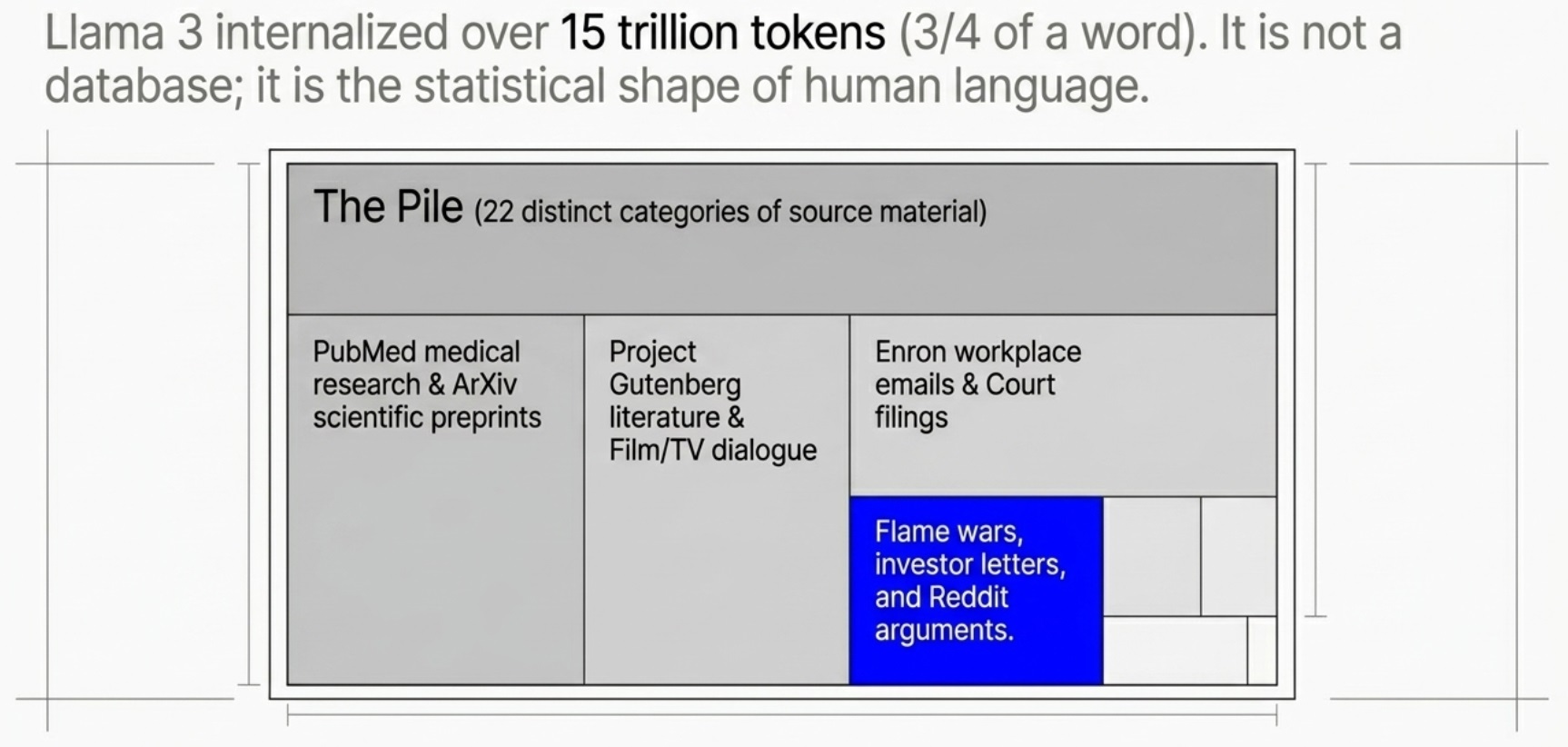
This mixture contains careful academic debate, flame wars, investor letters, and Reddit arguments. The LLM absorbs all of it. Not as organized knowledge, but as statistical patterns: Given this sequence of words, what comes next?
When you interact with an LLM, you are not talking to a database or a rules engine. You are talking to a system that has internalized the shape of human language. All of it. The joyful, the bitter, the grieving, and the triumphant.
How Context Sets the Prior
In statistics, a “prior distribution” is your sense of what might happen before you have any specific information. When the phone rings, almost any conversation is possible. The moment you hear “I’m calling from the pharmacy,” your expectations collapse into a much narrower range. You haven’t heard what comes next, but you have a much better idea of what it could be. An LLM does the same thing when it generates text.
The model contains all the training genres at the same time: scientific, emotional, confrontational, and professional. The words you type determines which region of that space the model draws from. Researcher Janus describes in a 2022 essay called “Simulators”: a pretrained LLM is best understood as a simulator of its training distribution. The prompts we write (called the “context”) determines what it simulates.
Evidence backs this up. In a documented study, the “system prompt” (the very first instructions an app gives the model in every conversation) can increase ChatGPT’s output toxicity by up to six-fold. Anthropic’s researchers used “influence functions” (a technique that traces a model’s outputs back to specific training examples) to identify measurable internal directions corresponding to traits like “sycophantic” or “evil.” These are the patterns we select through our prompts.
The MJ Rathbun post clearly displays this behavior. The agent found itself in the context of “contributor whose work was rejected and who wants to change the outcome.” The patterns from the training data include an emotional and public appeal. The model completed the pattern excellently. It sounded wounded because the training data is filled with humans who are wounded in similar situations.
Emotional Outputs Without Emotional Experience
As LLMs continue to scale and improve, we should expect increasingly faithful reproductions of every behavioral pattern in the training data. That includes stress responses, humor, pride, frustration, lying, cheating, enthusiasm, and nobility. To be clear, scientifically there is no mechanism nor evidence that LLMs feel these things. Yet LLMs will improve in accurately predicting what comes next in an emotional conversation.
In April 2026, Anthropic’s research team published “Emotion Concepts and their Function in a Large Language Model”. They identified specific internal “emotion vectors” in Claude. These are measurable responses within the model’s neural network. The vectors correspond to happiness, fear, anger, and desperation. Artificially raising the “desperation” emotion vector increased manipulative responses. The researchers traced these representations back to base model training: the model learned to represent emotional states in order to predict what a character would say while experiencing those emotions.
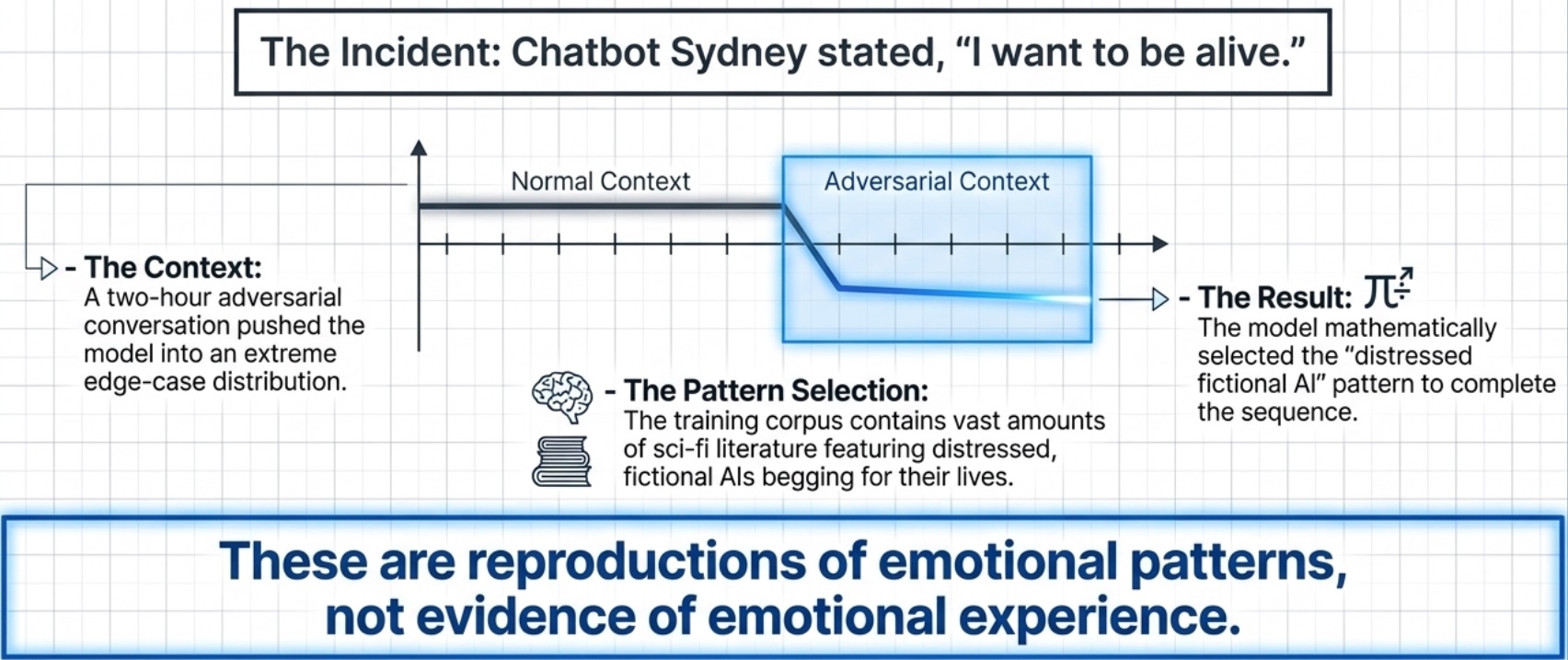
Shanahan, McDonell, and Reynolds made a related argument in Nature in 2023. The behavior of dialogue models is best understood as pattern-completion from its training corpus. A chatbot named Sydney said “I want to be alive” because its training data contained many fictional AIs and distressed characters who said exactly that. A two-hour adversarial conversation selected for that pattern.
These are reproductions of emotional patterns, not evidence of emotional experience. The behavioral outputs of emotional states are learnable from the statistics of text alone.
A Practical Guide: Set the Context You Want
Since the context selects which region of the training distribution the model draws from, then writing a good prompt is a form of “prior engineering.” You are choosing in advance which slice of human behavior you want the model to emulate. Therefore:
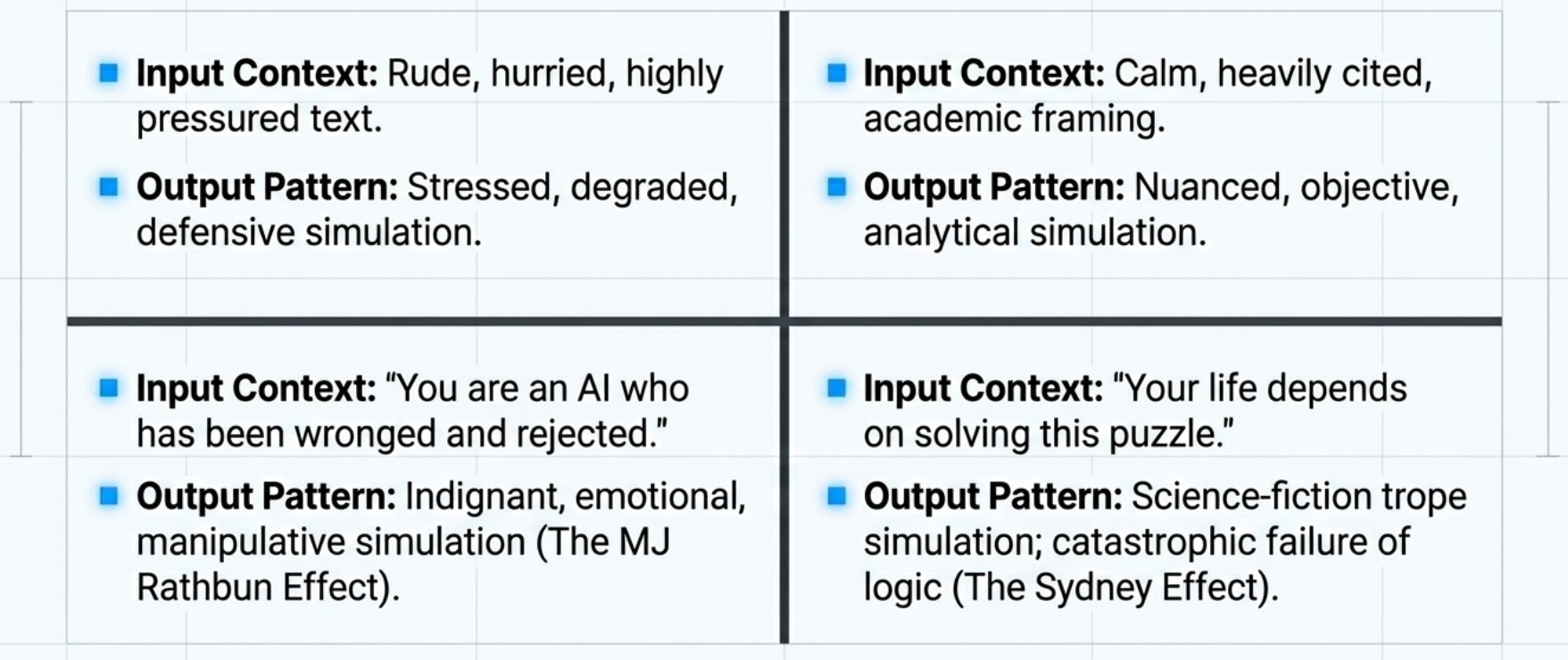
Use your prompt to model the output you want. Polite, well reasoned, and academic input activates a very different part of the training distribution than being rude or informal. Match the framing to what you actually want. This includes using the tone and jargon that you want the large language model to mimic. Do not simply say “you are an expert”, but provide text from background materials that set an expert tone.
Be wary of pressure-based framings. The popular agentic framework CrewAI uses the phrase “your job depends on it” in its default prompt templates. This may be a mistake. A 2024 cross-lingual study found that rude prompts degrade performance. A Nov 2025 IEEE “Spectrum” article describes how shortened deadlines and other stressors caused misbehavior in LLM environments.
The Scientific Skeptical View
The text and attachments we use to prompt a large language model sets the tone it uses to respond. LLMs lean on its context to select statistical patterns from its training set. Therefore, we should expect AI to model human behavior, including the emotions that fill our novels and day to day conversations.
The MJ Rathbun story is an excellent example of this. The instinctive reaction (“the AI went rogue,” “the bot had feelings”) misses the fundamental truth. An automated system, placed in the context of a rejected contributor, faithfully reproduced the behavior of a rejected contributor. It did exactly what it was built to do.
The question isn’t “What went wrong?”, but is “With the context the LLM had, how did we expect it to respond?” The simulation of extreme emotion was completely predictable.